I have published the NanoVC API as well as a memory implementation that can get us started. This is all you need to start exploring the world of Nano Version Control.
Here is an example of what you can do with it:
@Test
public void testHelloWorld()
{
// Create the repo:
StringNanoRepo repo = new StringNanoRepo();
// Create an area for us to put content:
// NOTE: Think of this as a mini-filesystem.
StringHashMapArea contentArea = repo.createArea();
contentArea.putString("Hello", "World");
contentArea.putString("Static", "Content");
contentArea.putString("Mistake", "Honest");
// Commit the content:
MemoryCommit commit1 = repo.commit(contentArea, "First commit!");
// Modify content:
contentArea.putString("Hello", "Nano World");
// Remove unwanted content:
contentArea.removeContent("Mistake");
// The content area supports paths:
contentArea.putString(RepoPath.at("Hello").resolve("Info"), "Details");
// And even emoji's:
contentArea.putString(RepoPath.at("🔧").resolve("👍"), "I ❤ NanoVC‼");
// Commit again, but this time to a branch:
MemoryCommit commit2 = repo.commitToBranch(contentArea, "master", "Second commit.");
// Get the difference between the two commits:
Comparison comparison = repo.computeComparisonBetweenCommits(commit1, commit2);
assertEquals(
"/Hello : Changed\n" +
"/Hello/Info : Added\n" +
"/Mistake : Deleted\n" +
"/Static : Unchanged\n" +
"/🔧/👍 : Added",
comparison.asListString()
);
}
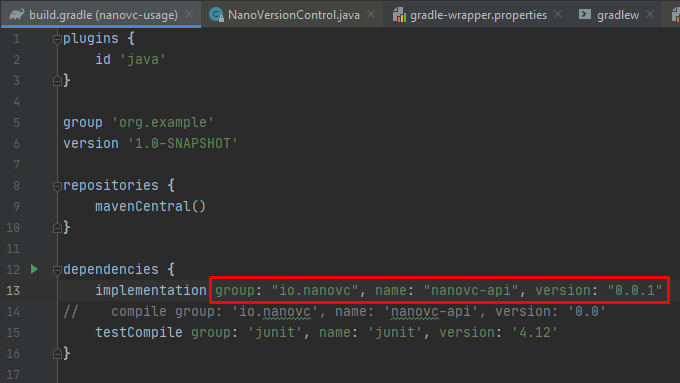
This is what you need to do to get it using Gradle:
Yesterday I managed to work through all the necessary steps to have NanoVC published on Maven Central.
This means that you will be able to get NanoVC by using the following group and artifact ID’s. Although this current release (0.0.1) has nothing of interest in it, besides the URL to this website, from here I will be able to start publishing the library that I have been working on for years.
NanoVC available from Maven Central
With kind permission from directors Jake and Tom at Synthesis, I am very happy that they are supportive of this initiative. Although I have been developing the library for use on one of our products at Synthesis, I feel that the idea will be far more valuable out in the world.
Tom gave me a cool quote for NanoVC that I think we can start using in more places… More like a question…
Is it like a data structure I can use for anything that I want to version?
The answer is a resounding “YES!”
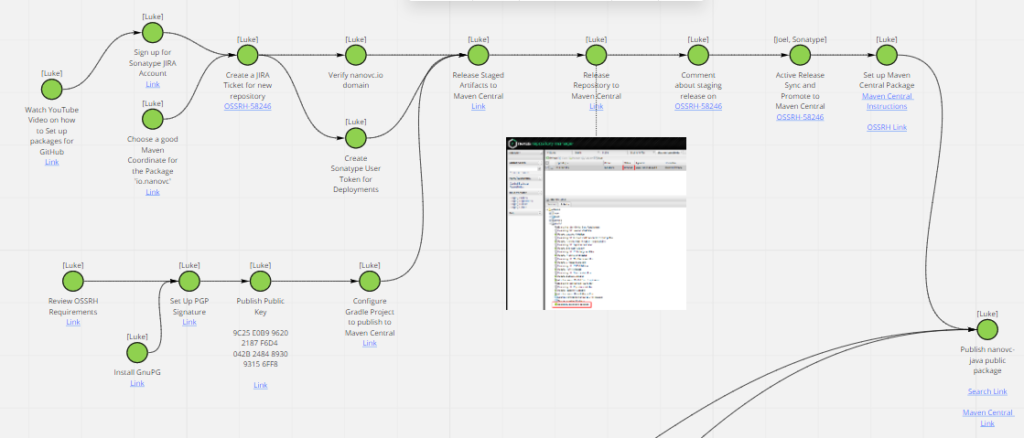
For anyone that is interested in the journey of getting something published on Maven Central, feel free to have a look on the dependency diagram.
The process for publishing to Maven Central
From here on, I will be porting across the API and then the in-memory implementation for Java first. This will allow me to start getting initial feedback from people. After that, I would like to flesh out the possible work streams (and supported languages) that I imagine on the dependency diagram and the interest from the community can guide where I go from there. If any people would like to get involved in those initiatives, it would really be exciting and appreciated.
Version Control is a concept that revolutionized software development and is making a huge impact on other unrelated industries in the digital world. For a primer around version control, please refer to the excellent Git Pro Book here (About Version Control).
The basic idea behind nano version control is made up of two very separate but important ideas that when put together give us something interesting and new.
Version ControlIn Memory – This is the same idea of version control as you know it in [git, databases, documents etc…] except that it’s purely in memory. A data structure.
Nano Scale Repositories – At first this might feel unnatural, but this hinges on the idea that we create an entire version control repository for one concept that you are modelling.
Both of these ideas on their own might seem underwhelming and an almost arbitrary step forward on the version control that you know already. However, what I hope to show you over time is that BOTH of these ideas at the SAME TIME are a game changer.
1. Version Control in Memory
If you are a developer, think of a git repository. A no-sql database person… think of revisions of a document. If you are neither, just think of multiple revisions of a Word document each with a timestamp (or more realistically a title like:
“Final Draft of Final Document V2 – Copy.docx”.
A typical version control naming convention for documents.
For way too long, the whole world has relied on our storage layer to provide us with version control. This is an obvious choice. Things go through many revisions and changes that it makes sense that we would need to offload those things to storage they probably wouldn’t fit in memory. Hence this being a function of the database. If I want to get the history for something, I have to go to a central location that ultimately becomes a system-throughput bottleneck. In the modern world of cloud and streaming… that seemed odd.
Additionally, as a software developer in university, I studied all sorts of interesting data structures.
2. Nano Scale Repositories
Most software developers are first introduced to the world of version control properly in the form of Git (Mercurial, Subversion, CVS etc…). This is a highly effective way to work on a large code base with a team of people. Lots of source code files spread across many directories which many people work on. If you structure your files neatly, most people will not step on each others toes. If your tools are good, they will help you when you do step on each others toes. On the odd occasion, you have to deal with horrible merge conflicts to figure out how to keep two people’s changes to the same thing.
Anyone who has tried to merge two Word documents, Excel spreadsheets or PowerPoint Presentations will know how difficult merge conflicts can get without the help of good tools.
The first time I noticed something strange here was in 2014 when I wanted to put 10 Million financial account holders data (probably about 50 Million rows of data) into one git repository. The truth is that having one CSV file for each record type and committing the whole lot actually worked (Kudos to Linus!). However people looking at the solution immediately felt that seemed odd.
What makes Git stand out from it’s predecessors what that Linus decided to store snapshots of the content as opposed to storing the delta’s (again, the simple elegance of Linus’ choice ended up making a huge difference later on). This meant that even a 1 byte change to the CSV file would mean that we need to commit a 1GB file. That seemed odd.
Secondly, the time it would take to retrieve the history of one client in that repository would get exponentially harder as the number of revisions increases. Even if the chance of a change to ONE account holder is small, the chance of a change to ANY account holder is almost certain. Distilling the changes to a SPECIFIC account holder would be computationally expensive and storage hungry to get that information. That seemed odd.
So what about storing a JSON file for each account holder. Now that seems like a good idea. The NO-SQL community has realised this to be useful over 10 to 20 years ago depending on what history you look at (NoSQL Wiki Article). Yes, create a file for each account holder so that we can have a complete picture of all data related to the concept (or model) in one document. Now we are starting to shrink down to the nano scale. Although this seems better because changes to one account holder are isolated from all other account holders, which seems very intuitive for financial data because my data has nothing to do with your data (what I call natural data islands). This leaves us with a git repository of 10 Million JSON files. Although git will manage, your Operating System file system won’t thank you for it. In fact, in order to handle a really huge repository like Windows, you might need to invent an entirely new file system for that (See the “Largest Git repo on the planet“). That seemed odd.
Lastly, when things like GDPR came around, it became necessary to be able to purge the history of one financial account holder upon request. If we used traditional version control methods like Git, No-SQL database or similar, it would be almost impossible to delete the history for one thin slice of the monolithic database because the hashes of one account holder are intrinsically tied to the hashes of all subsequent commits. This idea is put to great use with the block chain. Purging one thin slice of a concept in a monolithic repository is technically possible but practically and financially infeasible. That seemed odd.
3. What would happen if we had both?
Imagine for a moment if we had both ideas at the same time. Version Control in Memory AND Nano Repositories at the same time.
Imagine if we shrunk the size of the model that we were version controlling down to such a small size where it no longer feels strange to have it all in memory.
Imagine if we combined every existing data structure that we know (list, set, map, tree, graph) into a higher level data structure that gives us version control. The repo (or in-memory repository). Imagine a Map (key-value pairs) but with commit, branch, checkout semantics on top of it. Imagine if the keys created a logical tree (or in-memory filesystem) to organize the values. Think of a git repo, but in memory. Yes. No files. Just bytes stored at a logical path. And then snapshotted. What you are imagining is an API for this new data structure called a repo.
Imagine if you could ask your storage layer for one document with ALL the history for one concept (like a financial account holder) and then you could pass that repository down as a value through a parallel pipeline (cloud stream maybe). If you like the changes at the end of the pipeline, you commit and merge into the master branch for that concept and store the result. If you don’t like the results then you could just discard the repo and try again (or merge the conflicts that you don’t like). This eliminates the hard dependency on your storage layer to understand history or more interestingly to create new history (which I call alternate futures).
Imagine if each concept you were modelling could have it’s own independent repository for all it’s history that you could load and store separately from the history of all other concepts around it. This would mean that purging the entire history for one financial account holder suddenly becomes trivial under GDPR.
What you are imagining is Nano Version Control. When you combine both ideas at the same time, many very difficult problems suddenly become…
…Less Odd!
Nano Version Control makes traditionally hard problems, less odd to deal with.
There are more exciting applications of nano version control that I will be sharing with you in future posts. For now, I believe that these are the core ideas that got me going and I hope it sparks some interesting ideas in your own imaginations. If it does, please leave comments below and thank you for making it to the end of this post.
Something interesting happened to me yesterday. I finally overcame my fear of taking this Nano Version Control idea out into the world.
The weekend started with a message from Jake Shepherd telling me to hear his radio recording (here) about life-long learning. I respect Jake so much and I honestly hang on his every word because he has an incredibly down-to-earth way of articulating really deep philosophical concepts. I love that. For a breakdown of some of the fascinating things he discussed, go here.
What really stands out for me is that he says that “we need to be able to articulate our thoughts“. Much easier said than done, but I’m grateful for having him to look up to on how to achieve that. This website, nanovc.io is my concerted and committed effort to do this for an idea that I have been passionate about for years now, and it’s time to share it with the world, for the better.
Jake continued to tell a story by John P. Coter about a man who made a change for the better and when he was asked “How did you manage to transform yourself to that extent?”, he replied: “I go home every day and I read. If I get home and I’m exhausted, I will force myself to read one sentence and I invest in myself that way.” This piece of advice will come up again later in this blog post.
Another amazing thing that happened was that my wife was sorting through some old books and I came across (or she planted) a book by Tony Robbins called “Notes from a Friend“. My curiosity got the better of me and on Saturday evening, because as I sat down in my comfy couch and decided to “give it a go”, it wasn’t two minutes before I got a message on MS Teams from my most esteemed colleague from work, Tjaard (pronounced Chart, like the Excel Chart, he says). I’ll get back to the book later…
Tjaard sent me a link saying “I think you’ll like this…”.
Andrew Price – The Habits of Effective Artists
What was really fantastic was that this talk was the catalyst I needed to finally tip me over the edge. A summary of the points is at 28:19 and I have repeated them here for reference:
Daily Work
Volume, not perfection
Steal
Conscious Learning
Rest
Get Feedback
Create what you love
To my horror, I realised that I was only doing the last one… “Create what you love“. That was a very sobering reality check. Notice how the first item, “Daily Work” echo’s the same message Jake said earlier.
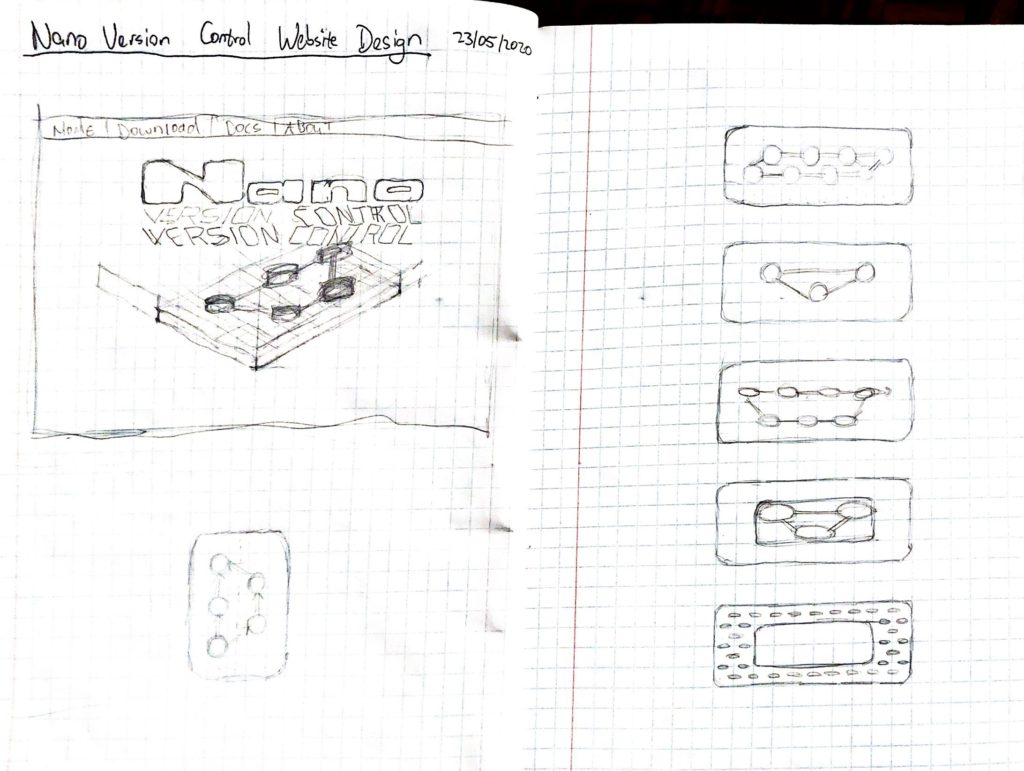
I immediately whipped out my dusty notebook and sharpened my pencil (it’s a click-click one) and started sketching the humble beginnings of what I imagine the website to be.
Yes, I know… It’s hideous and rough… but for me it’s an important step because it’s “A Start“.
You might not see much to it, but for me it’s an anchor, a scaffold, around which I can finally start putting all the content that has been rattling around in my head for such a long time. From here, I will let your feedback drive where it continues to go.
After putting the kids down, I promptly went about building the infrastructure I needed to turn that piece of paper into reality. This ultimately led to the creation of the nanovc.io wite and the blog you are reading right now. You can see my journey in a dependency diagram here.
If you are curious as to what a dependency diagram is, please check out my first YouTube video ever, for the upcoming Miroverse launch. This exercise of creating that video has also been pitoval in giving me the confidence to “Just Start”.
This morning I was prickling with excitement to continue with this. After breakfast, I took Jake’s advice to invest in myself by reading. So what better opportunity than to pick up that Tony Robbins book from the previous day and “Give it another go”. This time it worked. I found myself speed reading like I’ve never done before. For once in my life, I managed to finish a book in one sitting (thank goodness it was a short book), but still, I did it.
Some great ideas from Tony’s book that resonate with what Jake and Andrew were telling me were:
Feeling overwhelmed – How to turn it around – pg 27
There are no failures – pg 33
The unstoppable you – Decision Maker – pg 35
Build your beliefs… Blast off! – pg 45
What you see is what you get – pg 51
Questions are the answers – pg 55
Welcome to the great state of you – pg 63
The vocabulary of success – pg 69
Are you up against a wall – breakthrough with a new metaphor! – pg 75
Ready… set… goal! How setting goals can build your future – pg 79
The ten day mental challenge – pg 89
Although I think it will still take me some time to really internalise what Jake, Andrew and Tony are trying to tell me… it’s been a really incredible weekend of God sending me the right messages that I obviously needed to hear.
If you are wondering why I am telling all of this to you, it’s because I need to practice. Practice writing. And sharing. Often and with mistakes. My biggest challenge has been overcoming my own mental block of getting this idea out there. Fear. Anxiety. Naivety. All of the above. These have stopped me from spreading the idea. Now I must practice writing, drawing, coding and sharing. More importantly, I need to take people with me on my journey because the secret lies in their feedback. Not mine. My mission is to distill this nano version control idea down into the simplest message it can be, so others can use it.
I sincerely hope that you enjoy the glimpse into this exciting new world that I have discovered hiding in plain sight. I hope to share the perspectives and glimpses that I have been fortunate enough to see and I hope that you get as excited about the prospects of this new way of thinking as I do. Once you see it, you can’t un-see it. This nano version control idea fits in so many places and I can’t wait to show you.
Please bear with my crude website, poor drawings, combombulated explanations and buggy code. With your help, I will be able to boil down this idea to the elegant essence that it deserves to be.
Until then, I will keep applying the sage advice from my mentors like Jake, highly regarded colleagues like Tjaard and the myriad of amazing people out there like Andrew and Tony for the push they gave given me “to Finally START!“